
As a software developer (or someone involved in higher level mathematics) you’ve probably heard the term “Big-O” used a lot. I remember skimming through my Introduction to Algorithms book in college and wondering what the heck “Big-O” was all about. It doesn’t go away once you enter the working force either. If you have to deal at all with computational performance and designing systems that can scale gracefully given extra workload, then you have to understand what “Big O” is all about.
Okay, I’ve now used the term “Big-O” multiple times and still haven’t suggested what this notation means! Sorry, just wanted to build up a little curiosity first (it’s good for memory retention!). Anyway….
Big-O, also known as “Big-O Notation” is just a way we, as software engineers or mathematicians, like to describe our algorithms. Big-O Notation is very commonly used to describe the asymptotic time and space complexity of algorithms. The term asymptotic means “approaching a value or curve arbitrarily closely”. In computer science and mathematics, asymptotic analysis is a method of describing limiting behavior. When we want to asymptotically bound the growth of a running time to within the upper constant factors, we use big-O notation for asymptotic upper bounds, since it bounds the growth of the running time from above for large enough input sizes.
I know it’s probably still a little unclear about what that means. Think about it like this; if we have an algorithm that does work on n amount of data inputs, as n grows (always approaching infinity) how will our algorithm grow in respect to it’s running time (time to complete the processing of n units) and its space in physical memory (typically how much RAM will be needed or used in respect to n growing to infinity).
Big-O is defined as the asymptotic upper limit of a function. In plain English, it means that is a function that cover the maximum values a function could take. Big O notation characterizes functions according to their growth rates: different functions with the same growth rate may be represented using the same O notation. The letter O is used because the growth rate of a function is also referred to as the order of the function. A description of a function concerning big O notation usually only provides an upper bound limit on the growth rate of the function.
| Growth Rate | Name |
|---|---|
| 1 | Constant |
| log(n) | Logarithmic |
| n | Linear |
| n*log(n) | Linearithmic |
| n^2 | Quadratic |
| n^3 | Cubic |
| 2^n | Exponential |
What these functions look like on a graph are as follows. You can see that as n (the input elements) approaches infinity for some of the algorithms, the operations taken to complete these algorithms grows VERY rapidly.

Alright, now I know that the last paragraph had a lot to take in, so I want to make it a little more concrete and precise by providing some examples and when we might use Big-O Notation to describe some common algorithms.
Probably the most common place you will see Big-O Notation is when you are reading about sorting algorithms. Big-O is the main way we describe these algorithms to allow the person using them to understand the performance of these algorithms and choice the correct algorithm for their situation based on the data sets and hardware limitations that they have.
Sorting Algorithms
1 2 3 4 5 6 7 8 |
|
Do you recognize this algorithm? It’s called Insertion Sort. It has two nested loops, which means that as the number of elements n in the array arr grows it will take approximately n * n longer to perform the sorting. In big-O notation, this will be represented as O(n2), or we could say the algorithm is a quadratic function (see the growth chart above).
What would happen if the array arr was already sorted? That would be the best-case scenario. The inner for loop will never go through all the elements in the array then (because arr[y-1] > arr[y] won’t be met). So the algorithm will run in O(n) time.
We are not living in an ideal world. So O(n2) will be probably the average time complexity.
This is just one of the many sorting algorithms that have been developed over the years, and in fact, it is not typically the best choice as a sorting algorithm to implement if you have a large data set to be sorted.
A more advanced sorting algorithm is Merge Sort. It uses the principle of divide and conquer to solve the problem faster.
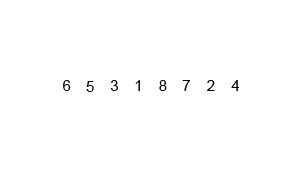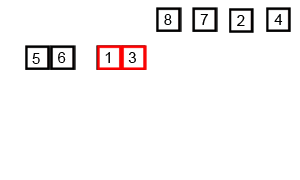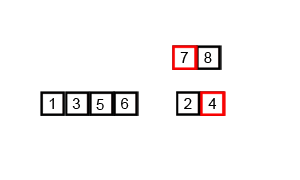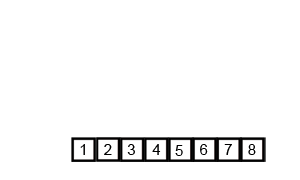
- Divide the array in half
- Divide the halves by half until 2 or 3 elements are remaining
- Sort each of these halves
- Merge them back together
This algorithm (as with most divide and conquer algorithms) will have a much more efficient running time and can be described in big-O notation as having a running time of O(n log(n)) which happens to be a very fast algorithm for sorting data elements.
So if merge sort is faster than insertion sort, why do we even have to be concerned with insertion sort (or any or the slower sorting algorithms for that matter). The reason is that we have only been considering its asymptotic time complexity and haven’t given thought to its asymptotic space complexity. The great time complexity of the merge sort algorithm didn’t come without a cost. In the case with merge sort, we are trading speed (time complexity) for memory (space complexity). This is sometimes okay, and sometimes it’s not. It all depends on your situation and the resources that you have at your disposal.
The asymptotic space complexity for merge sort happens to be O(n)…. This means that for every input element (n) we give this algorithm it will grow linearly with n. Now consider insertion sort which has a asymptotic space complexity of just O(1). That is about as good as it gets regarding asymptotic analysis. When an algorithm is described as an O(1) algorithm, that means that n can get as large as it wants but it will have NO EFFECT on the algorithm. This is known as a constant function.
Therefore, you could use this knowledge to apply the insertion sort algorithm with its low memory overhead relative to n if you have a very limited amount of memory to use for your processing. However, if memory is less of a concern then you most likely would like to use merge sort and use more memory to have substantial performance gains in large data sets.
Consider the following table to realize the difference in time complexity (speed) of the algorithms based on differently sized data sets and I think you can see why it is important to understand when and where to use the correct algorithm.

Big-O Time and Space Complexities for Insertion Sort and Merge Sort:
| Algorithm | best | average | worst | space complexity |
|---|---|---|---|---|
| Insertion Sort | O(n) | O(n2) | O(n2) | O(1) |
| Merge sort | O(n log(n)) | O(n log(n)) | O(n log(n)) | O(n) |
Notice that the table also shows the space complexity. How much space the algorithm takes is also an important parameter to compare algorithms. The merge sort uses an additional array and that’s way its space complexity is O(n); however, the insertion sort uses O(1) because it does the sorting in-place.
Big-O looks intimidating at first, but just remember that it is just a quick and easy way to describe how a particular algorithm will perform if its input size grows towards infinity. Knowing and understanding this notation will quickly help you as a developer to chose the correct algorithm for the right job and help you and your team from making a mistake that could cost you O(2^n) time!!
I hope you enjoyed this post and that it spread some light on a topic that is not always explained well in school or to beginner software engineers. Let me know of any other useful resources to describe Big-O or how it’s helped you in your algorithm development! As always if you liked this post, please subscribe to my blog to get the latest updates to my blog at jasonroell.com! Have a great day!